Typen:Objekte des selben Typs mit zusätzlichen EinschränkungenKonstrukte/Folgerungen:Involvierte Definitionen:Veranstaltung: EMLReferenz:- @thimm2024 (Abschnitt 5.1.4)
- @grant2024 (Backpropagation calculus | Chapter 4, Deep learning)
⠀
Theorem: Berechnung der partiellen Ableitung bezüglich eines Gewichts
Sei
ein gelabelter Datensatz.
Sei ein Neuronales Netzwerk gegeben mit
Schichten, - jeweils
Neuronen pro Schicht und - Gewichten
, wobei . Sei
der Fehler zwischen dem Label und der Vorhersage für ein Beispiel . Wir erhalten die partielle Ableitung von
bezüglich des Gewichtes zwischen
- dem
-ten Neuron der -ten Schicht und - dem
-ten Neuron der -ten Schicht, - also
für ein Beispiel
durch
Beweis
Abweichende Schreibweise
Im Folgenden benutzen wir Grant Sandersons Schreibweise
Wir führen den Beweis in zwei Teilen. Zunächst für ein vereinfachtes neuronales Netzwerk mit jeweils einem Neuron pro Layer. Dann für den generellen Fall.
Simples Netzwerk
Sei ein simples Netzwerk mit drei versteckten Schichten gegeben. Jede Schicht enthalte genau ein Neuron. Als Fehlerfunktion
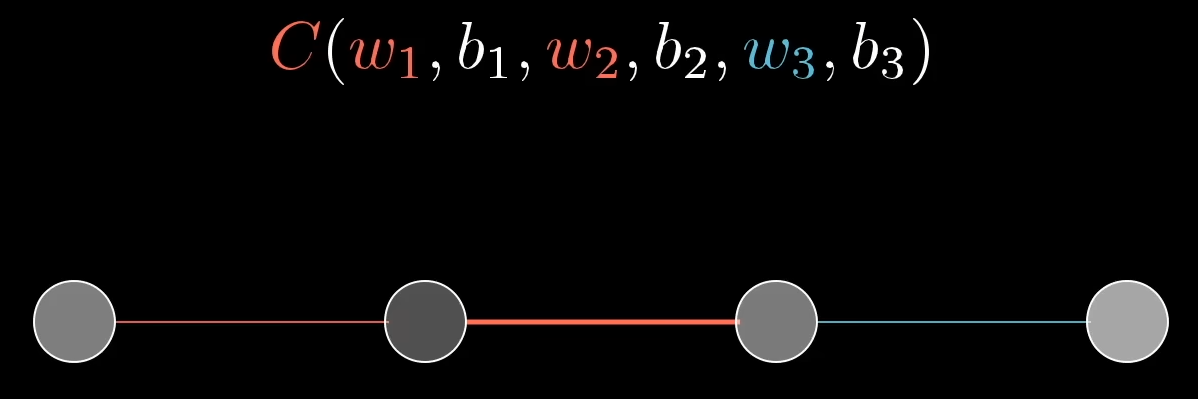
Konzentrieren wir uns zunächst nur auf die letzten beiden Neuronen:
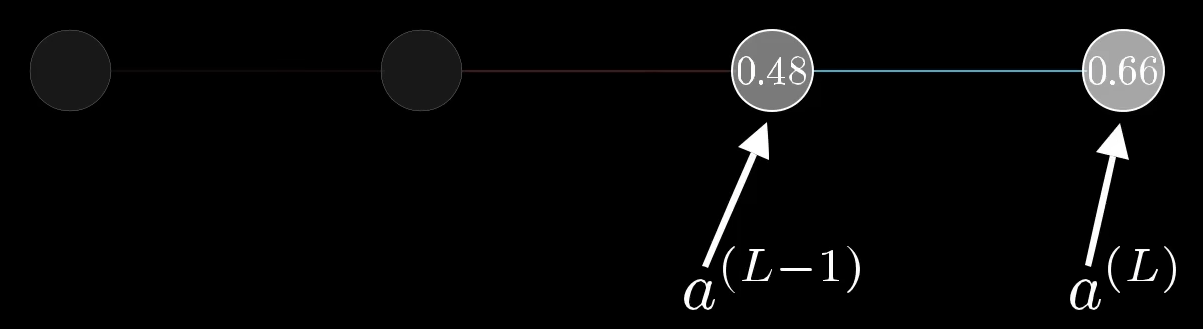
Die Werte
wobei
Den Wert der Fehlerfunktion erhalten wir schließlich durch
Für die Berechnung der Fehlerfunktion
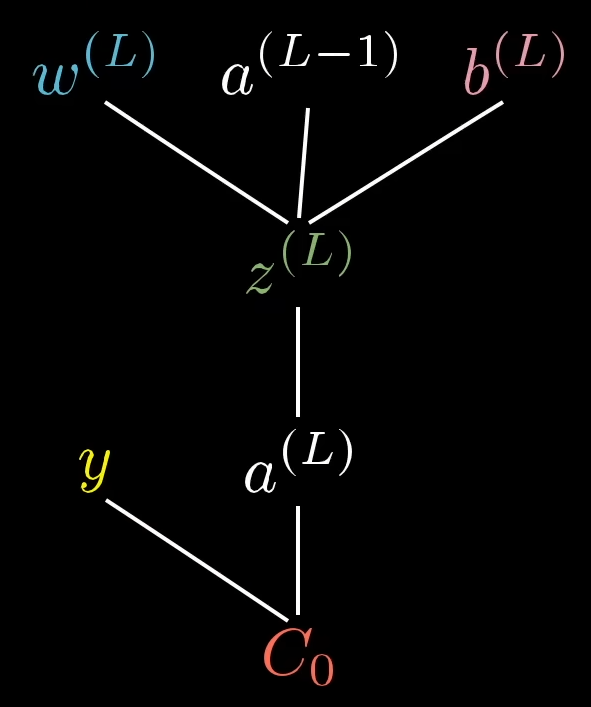
Ableitung bezüglich des letzten Layers für
Wollen wir nun das Gewicht
Mit Hilfe der Kettenregel erhalten wir diese durch
Das entspricht auch genau der Reihenfolge der Inputs:
Wir berechnen nun nacheinander die jeweiligen partiellen Ableitungen:
Die komplette Ableitung erhalten wir also durch
Ableitung bezüglich des letzten Layers für
Wollen wir nun bezüglich
Für
Wir erhalten also:
Iteration für
Wenn wir nun die Ableitung bezüglich
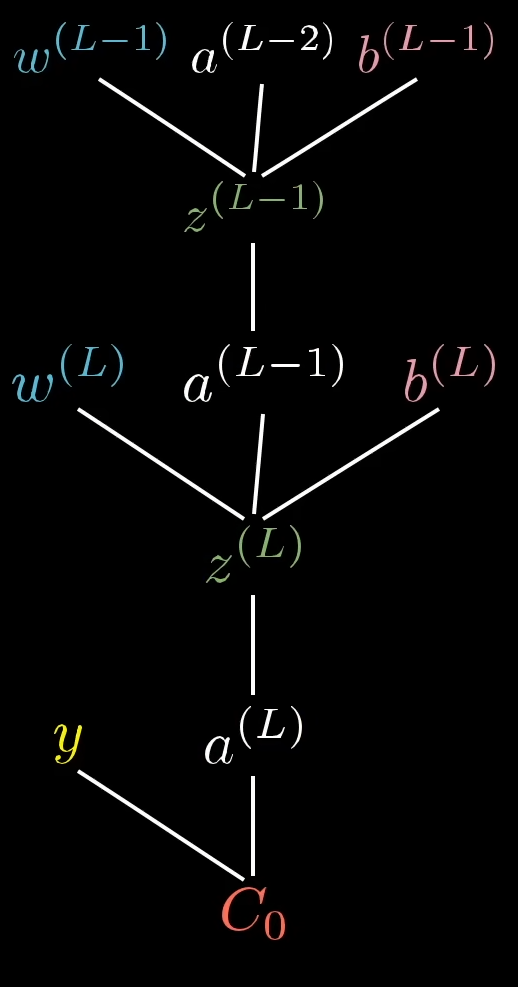
Die Partielle Ableitung
Allgemein gilt:
Generelles Netzwerk
Sei nun ein Neuronales Netzwerk mit mehreren Neuronen gegeben:
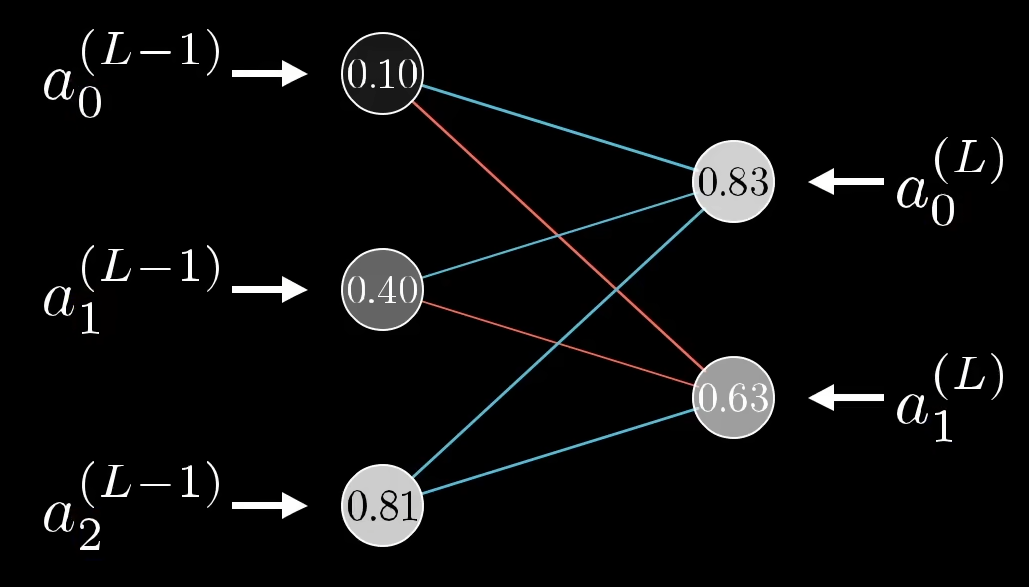
Die Werte
wobei
Die Fehlerfunktion
Ableitung bezüglich des letzten Layers für
Wollen wir nun das Gewicht
Wie zuvor erhalten wir diese mit Hilfe der Kettenregel durch
Wir berechnen nun nacheinander die jeweiligen partiellen Ableitungen:
Interessanterweise sind die erhaltenen Ableitungen also annährend identisch zu dem Fall des einfachen Neuronalen Netzwerkes.
Die komplette Ableitung erhalten wir durch:
Die Ableitung bezüglich
Iteration für
Wenn wir nun die Ableitung bezüglich
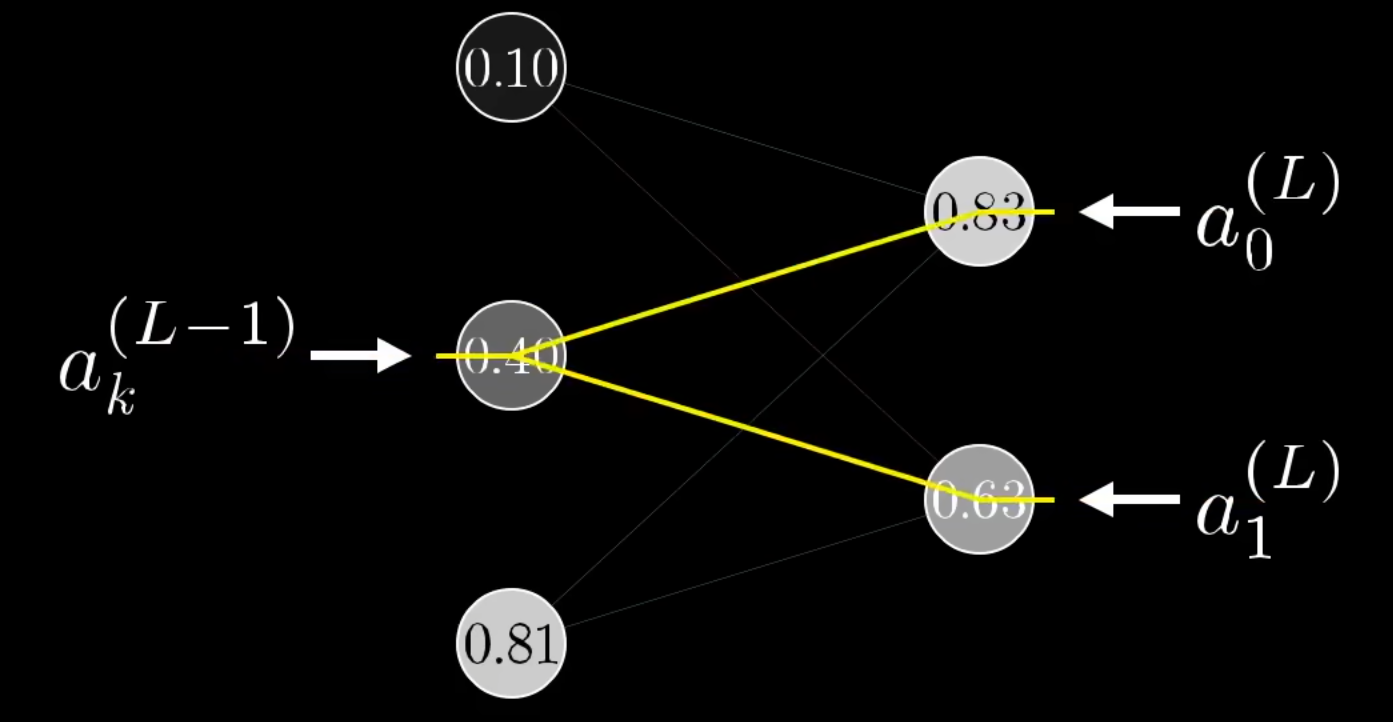
Konkret bedeutet das, dass wir die Summe aller Einflüsse bilden müssen.
Um die Komplexität zunächst so gering wie möglich zu halten, rechnen wir an einem konkreten Beispiel. Uns interessiert die Ableitung
Etwas allgemeiner erhalten wir die Ableitung
Bezüglich eines beliebigen Layers
Für ein beliebiges Gewicht
Erweiterte Darstellung des Mittelteils
Hier noch mal eine erweiterte Darstellung der Ableitungen von Output Layer
bis hin zu Layer .
Durch Anpassung der Schreibweise von Grant Sandersons an unsere Schreibweise ergibt sich
was zu zeigen war.