Referenz: @storl2024 (KE5, Analyse von Big Data; Teil 2 und Teil 3)
⠀
Definition: Apache Spark
Apache Spark ist ein Open-Source-Framework für die schnelle und universelle Verarbeitung großer Datenmengen.
Es bietet eine einheitliche Analyse-Engine für Big Data und unterstützt sowohl Batch- als auch Streaming-Verarbeitungsmodelle.
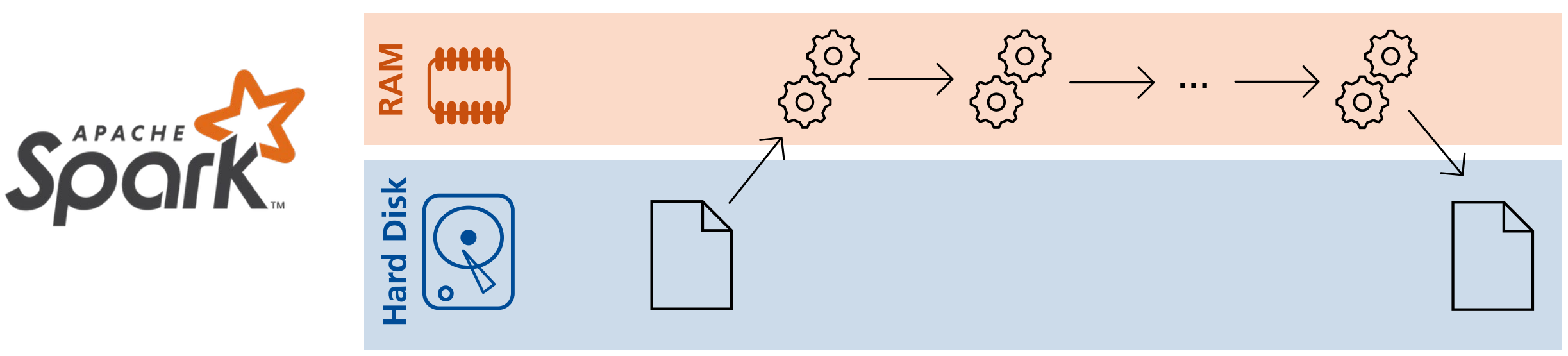
Dabei kann Spark als Erweiterung eines Hadoop Clusters und dort als Alternative zu Hadoop MapReduce betrieben werden, kann jedoch auch unabhängig von Hadoop eingesetzt werden.
Anders als in Hadoop werden die Daten in Spark erst nach Abschluss der Map-Schritte persistiert. Das bedeutet aber auch, das Spark im Default keinen Cache der Daten vorhält.
Anmerkung
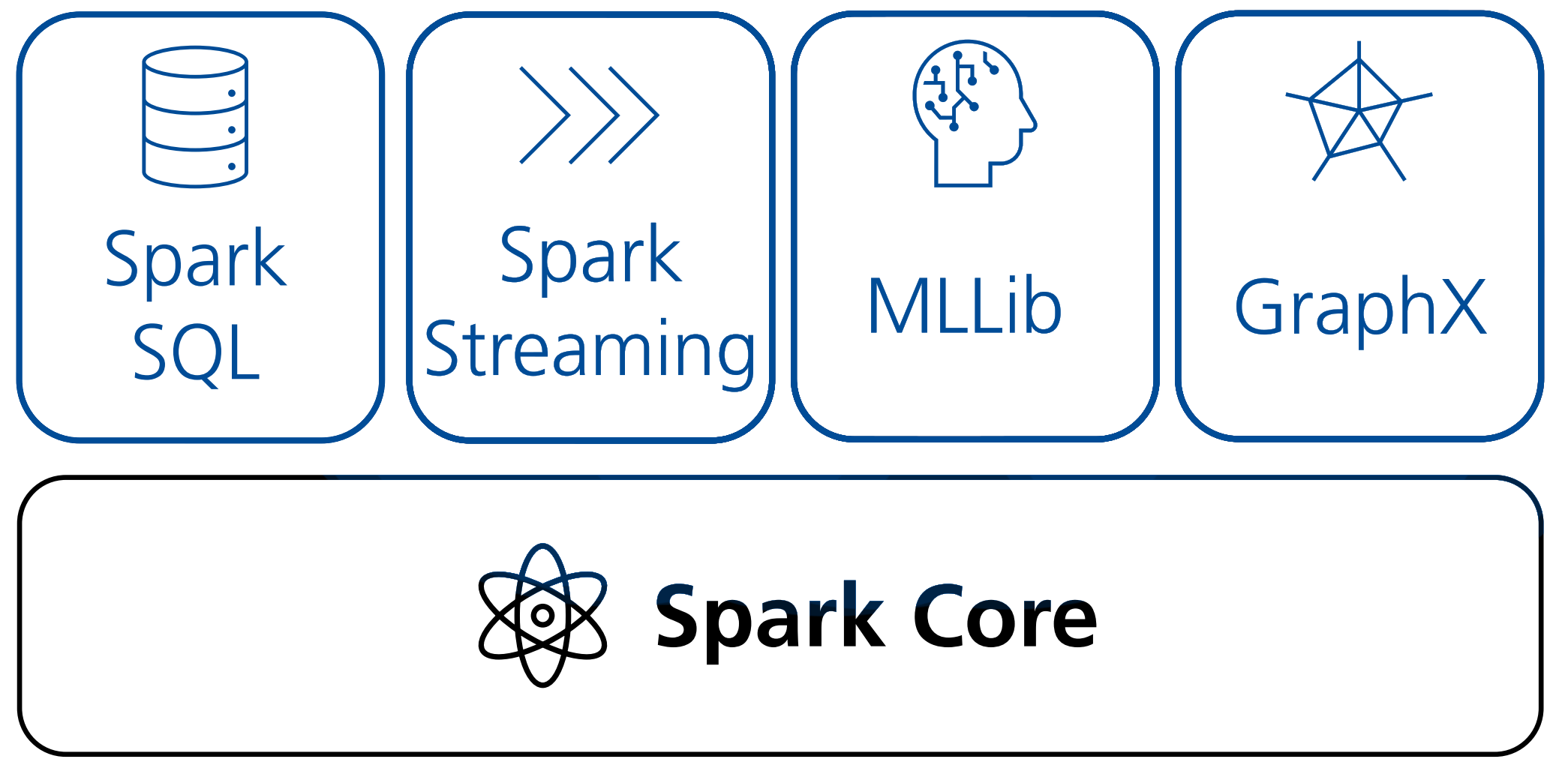
Spark Ökosystem
Ähnlich wie Hadoop bietet Spark ein (wenn auch kleineres) Ökosystem an Erweiterungen:
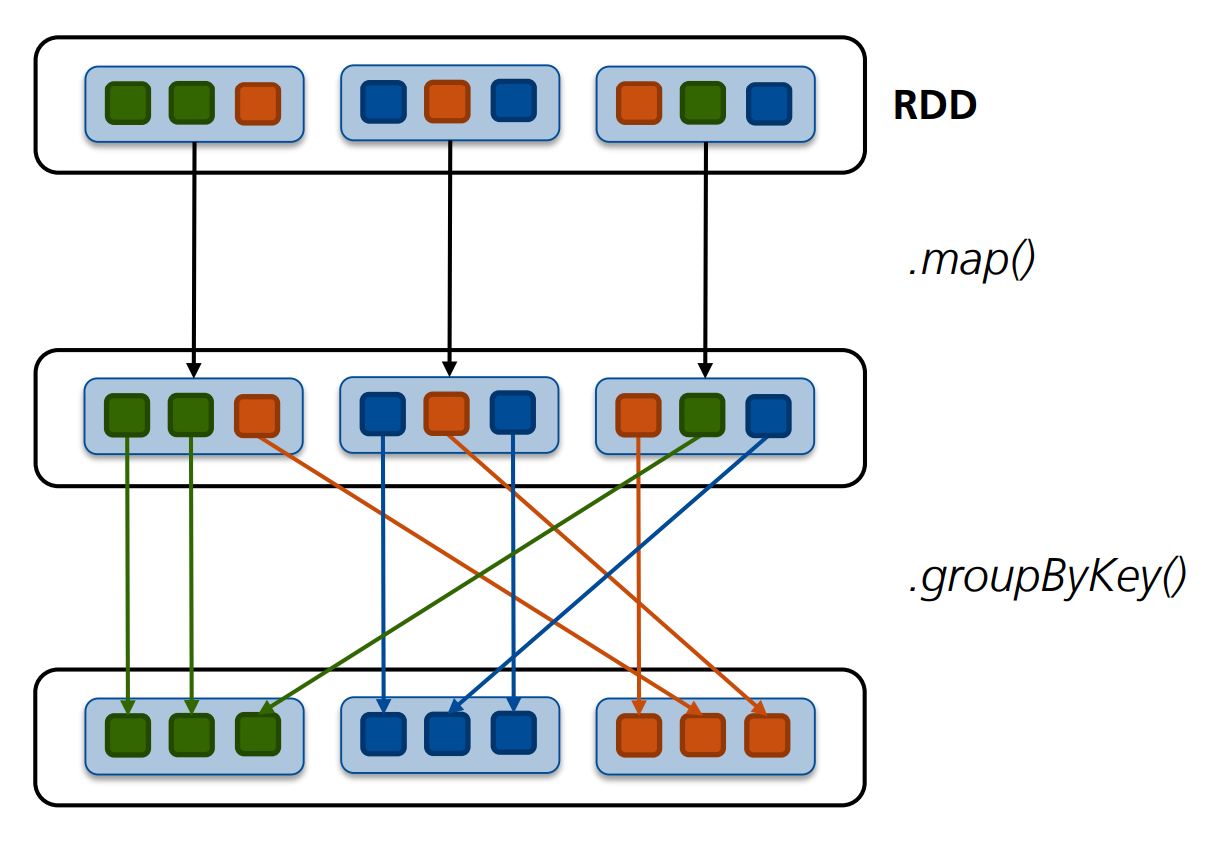
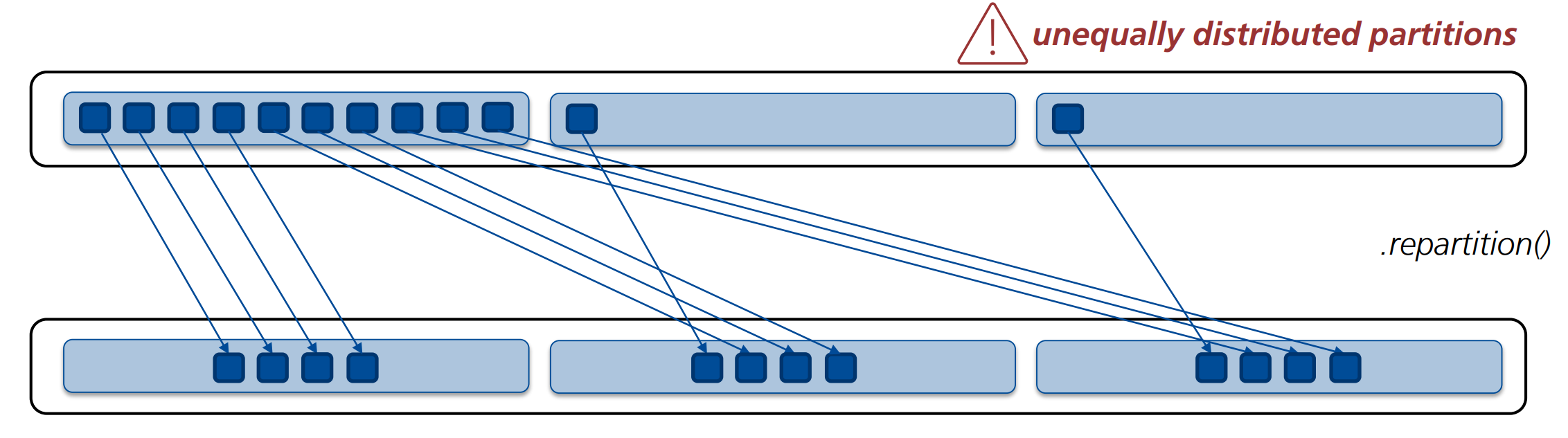
Definition: Shuffling und Repartition
Wie bei Hadoop MapReduce gibt es bei Spark (aufwendige) Shuffling-Schritte, bei denen die Daten nach Key zusammengeführt werden, bspw. bei dem Task groupByKey.
Diese Repartitionierungsschritte können jedoch auch nützlich sein, bspw. wenn nach einem Filter-Schritt nur noch wenige Datensätze eines Keys auf einer Node vorhanden sind.
Beispielhaftes Spark Programm
Als beispielhaftes Spark Programm, hier die Zählung aller Studierenden nach Fakultät, wobei folgendes CSV gegeben sei: