Typen:Konstrukte:Involvierte Definitionen:Veranstaltung: DEDSReferenz: @storl2024 (KE5, Analyse von Big Data; Teil 3)
⠀
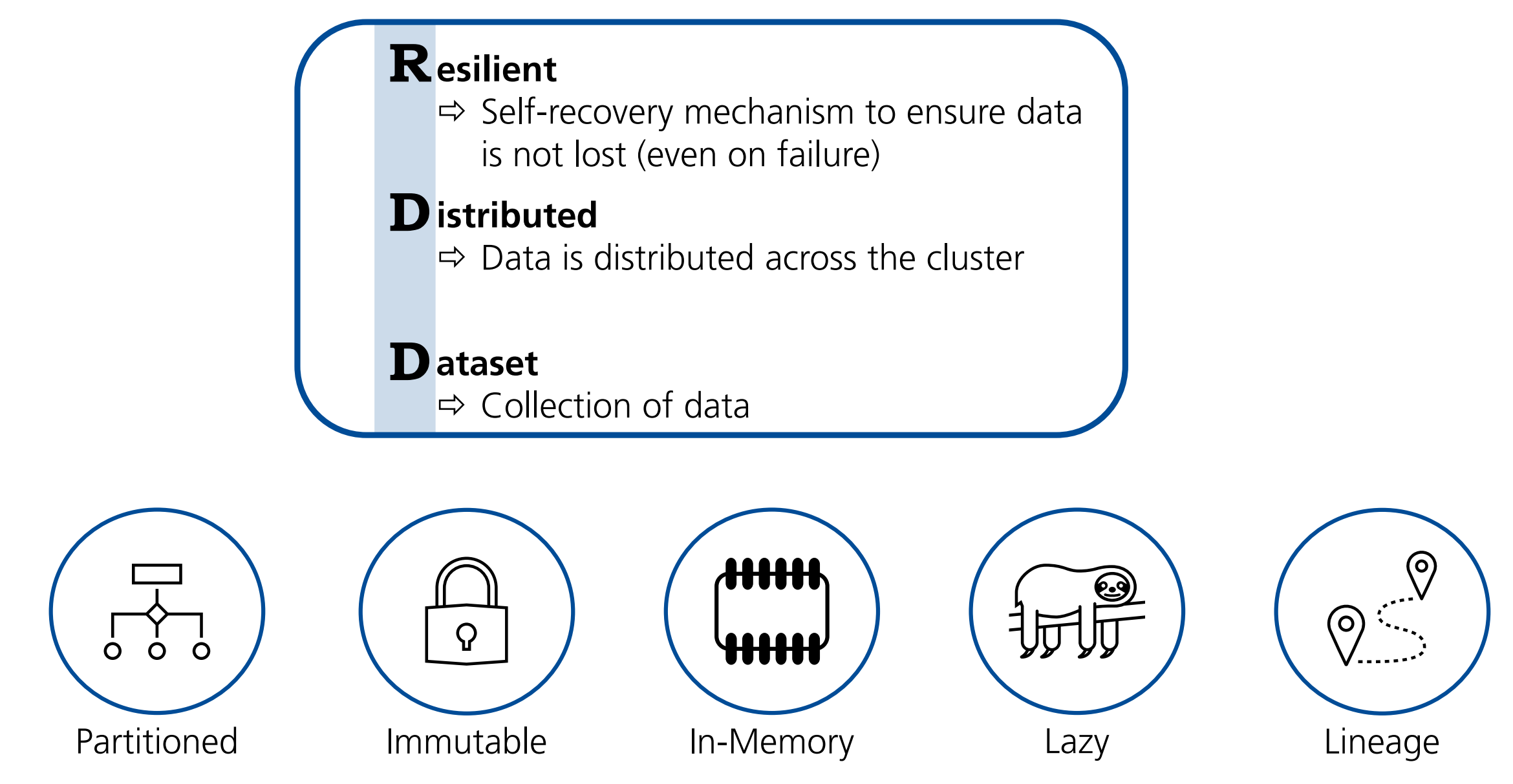
Definition: RDD
Als Resilient Distributed Dataset (kurz RDD) bezeichnen wir die grundlegende Datenstruktur in Apache Spark, die es ermöglicht, große Datenmengen effizient und fehlertolerant über mehrere Knoten eines Clusters hinweg zu verarbeiten.
Namensgebend für RDDs sind:
- Resilience: Auch in Fehlersituationen gehen keine Daten verloren
- Distribution: Die Daten werden über das Cluster verteilt.
Diese namensgebenden Eigenschaften werden umgesetzt durch die folgenden Konzepte:
- Partitionierung
- Unveränderbarkeit
- In-Memory-Verarbeitung
- Lazy Execution
- Lineage
Aspekte
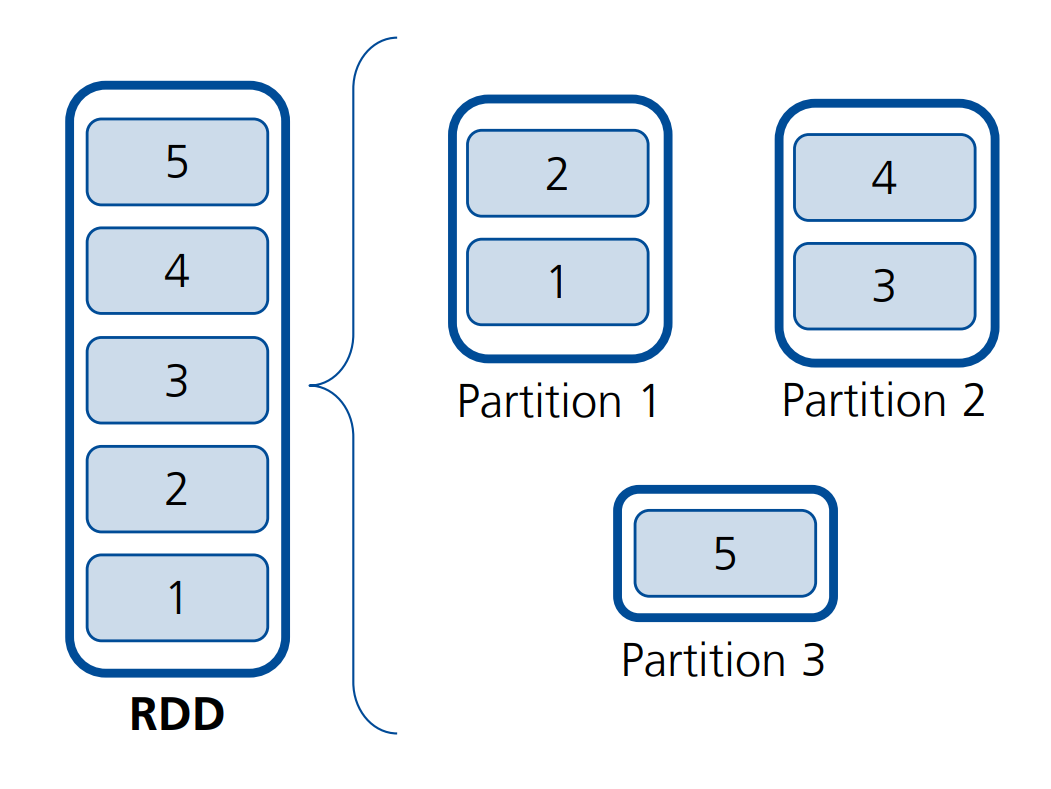
Definition: Partitionierung von RDDs
Die Elemente eines RDDs werden über die Nodes des Clusters hinweg partitioniert, wobei die genaue Anzahl der Partitionen auch konfigurierbar ist.
Jede Partition korrespondiert mit einem Analyse-Task.
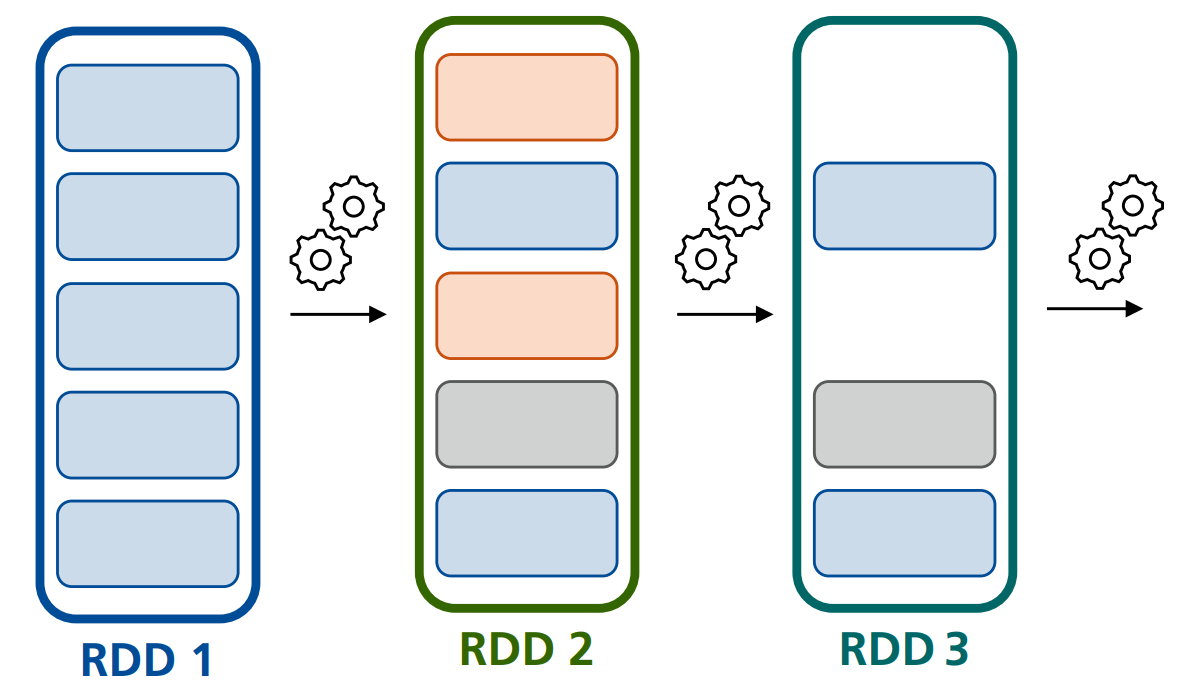
Definition: Immutability von RDDs
RDDs sind unveränderlich (en. immutable), was bedeutet, dass jede Operation auf einem RDD zu einer neuen Kopie des RDD führt.
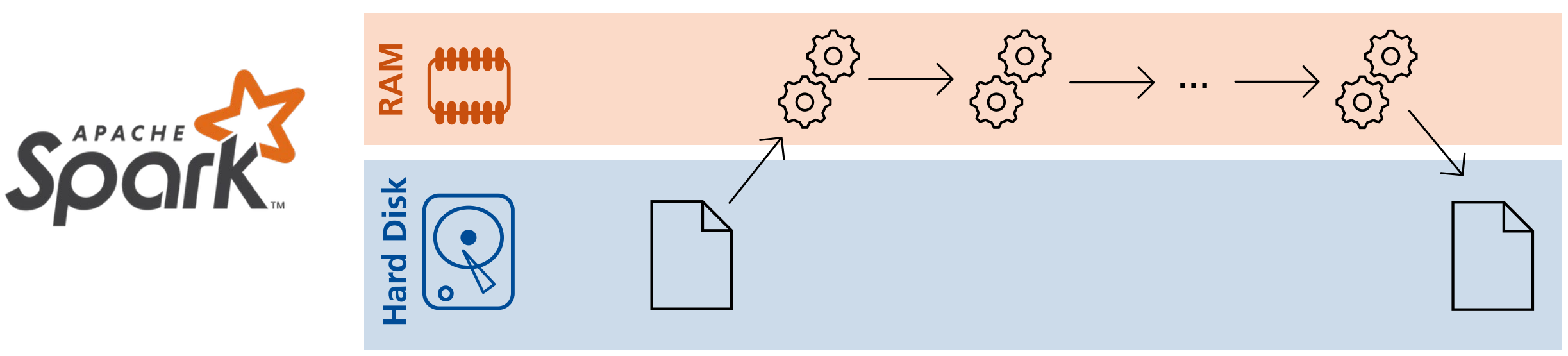
Definition: In-Memory Verarbeitung von RDDs
Anders als in Hadoop werden die Daten in Spark erst nach Abschluss der Map-Schritte persistiert.
Die Datenverarbeitung wird also vollständig in-memory durchgeführt.
Vorteile hiervon sind:
- Geschwindigkeit:
- Durch Minimierung des Festplatten-I/Os und das direkte Speichern der Daten im RAM wird die Verarbeitungsgeschwindigkeit deutlich erhöht.
- Speicherverbrauch:
- Da nicht jede berechnete Zwischenversion der Daten persistiert wird, benötigt das Spark-Cluster weniger Speicherplatz.
- Datenwiederverwendung:
- Durch das Caching von RDDs oder DataFrames können die Daten aus dem RAM direkt in anderen Berechnungen wiederverwendet werden.
Jedoch kann die in-memory-Verarbeitung auch an ihre Grenzen kommen:
- Out-of-Memory:
- Falls die Nodes nicht über genug RAM verfügen, um die Daten zu laden, stößt die In-Memory-Verarbeitung zwangsläufig an ihre Grenzen.
- Das kann insbesondere dann auftreten, wenn die Daten ungleichmäßig über das Cluster verteilt sind.
- Datenstreams:
- Treffen neue Daten eines Datenstreams schneller ein, als sie verarbeitet werden können, kann es zu Engpässen kommen.
- In dem Fall kann es notwendig sein, die Daten bis zur Verarbeitung persistiert vorzuhalten
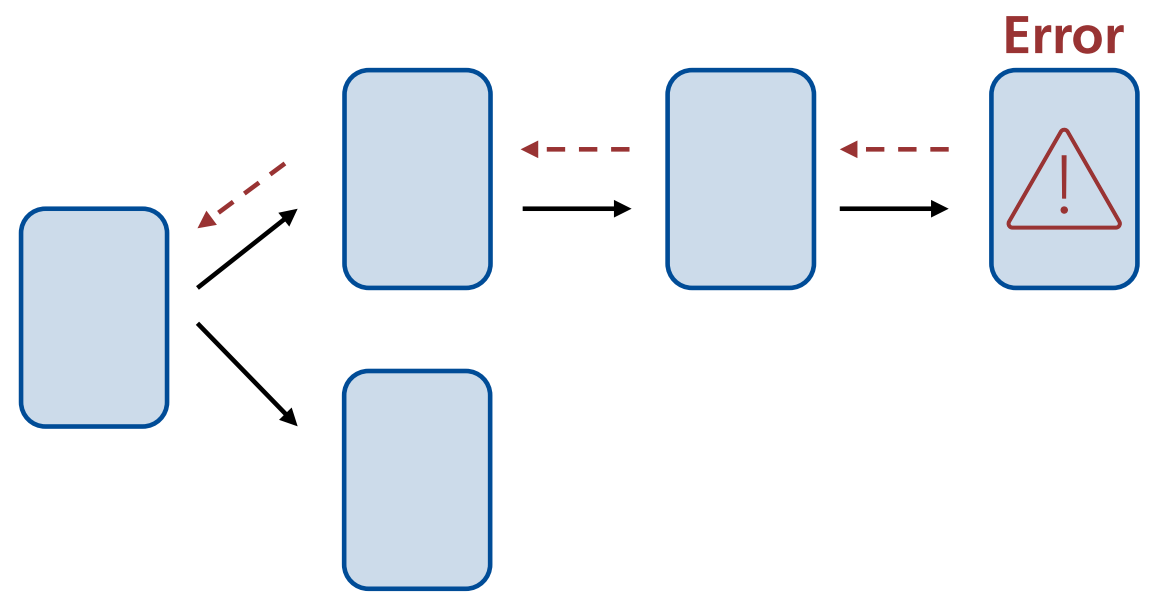
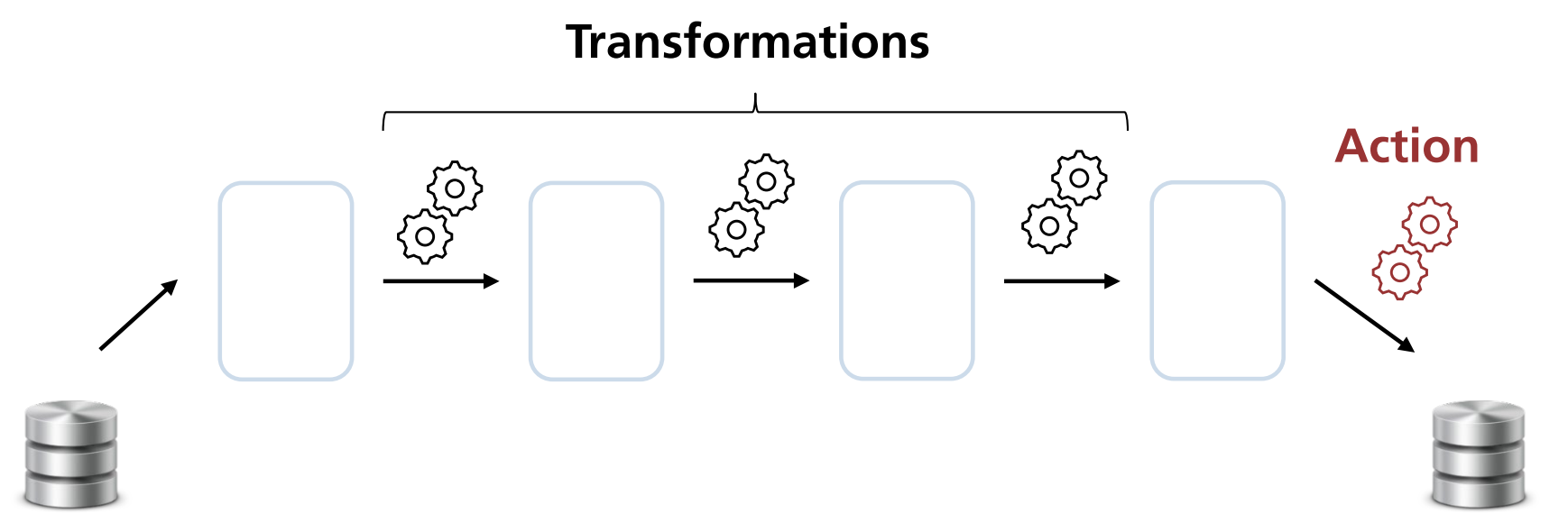
Definition: Lazy-Evaluation von RDDs
Spark definiert einzelne Tasks, bspw. Transformationsschritte.
Diese Tasks erzeugen logisch zwar stets ein neues RDD, werden jedoch nicht sofort ausgeführt, sondern zunächst in einem Lineage-Graphen aufgezeichnet.
Die eigentliche Ausführung und Berechnung erfolgt erst dann, wenn eine bestimmte “Trigger-Action” aufgerufen wird.
Dadurch kann Spark die Ausführung der Schritte optimieren:
- Schritte können zusammengefasst werden,
- Überflüssige Schritte können entfernt werden.
Nachteile der Lazy-Evaluation sind:
- Fehler tauchen ggf. erst unerwartet spät auf (wenn die Action aufgerufen und der Code tatsächlich ausgeführt wird).
- Die Verarbeitung erfolgt erst beim Aufruf einer Action und somit evtl. später als es der unbedarfte Leser erwarten würde.
Definition: Lineage-Graph von RDDs
Die ausgewählten Tasks werden in einem Lineage-Graphen gesammelt.
So ist stets für jedes RDD klar, auf welchen Daten es basierte, und wie es in einem Fehlerfall erneut berechnet werden kann.