Involvierte Definitionen:Veranstaltung: DEDSReferenz: @storl2024 (KE5, Analyse von Big Data; Teil 5)
⠀
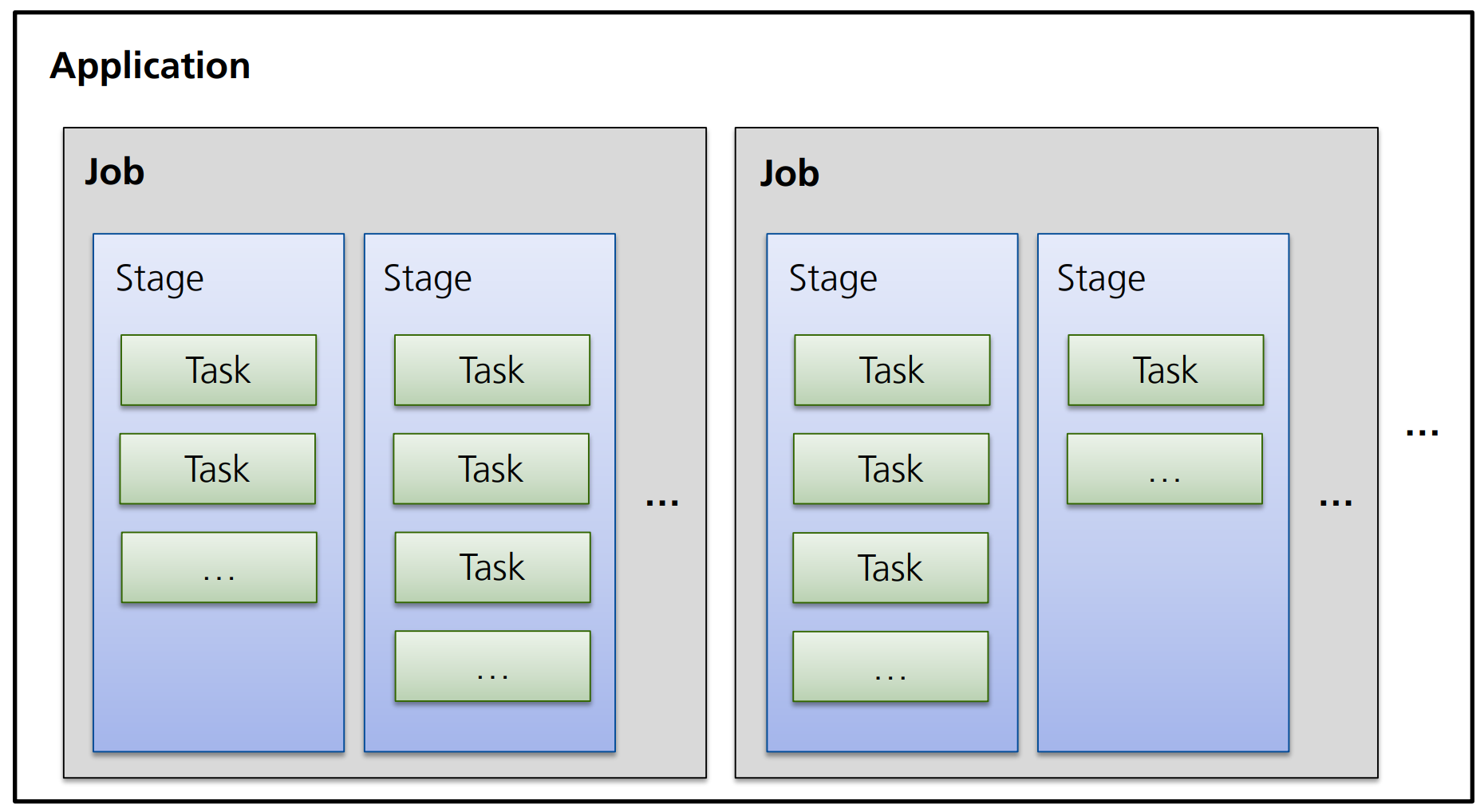
Definition: Tasks, Stages und Jobs
Die Grundbausteine von Spark Programmen sind:
- Tasks,
- Stages,
- und Jobs
Jede Operation (Filter, Map, Reduce) entspricht in Spark einem Task.
Diese Tasks werden durch den DAGScheduler zu Mengen (den sog. Stages) zusammengefasst, die ohne Shuffling der Daten ausführbar sind.
Ausgeführt werden die Stages mit ihren Tasks schließlich durch einen Job, der beim Aufruf einer Trigger-Action, erstellt wird.
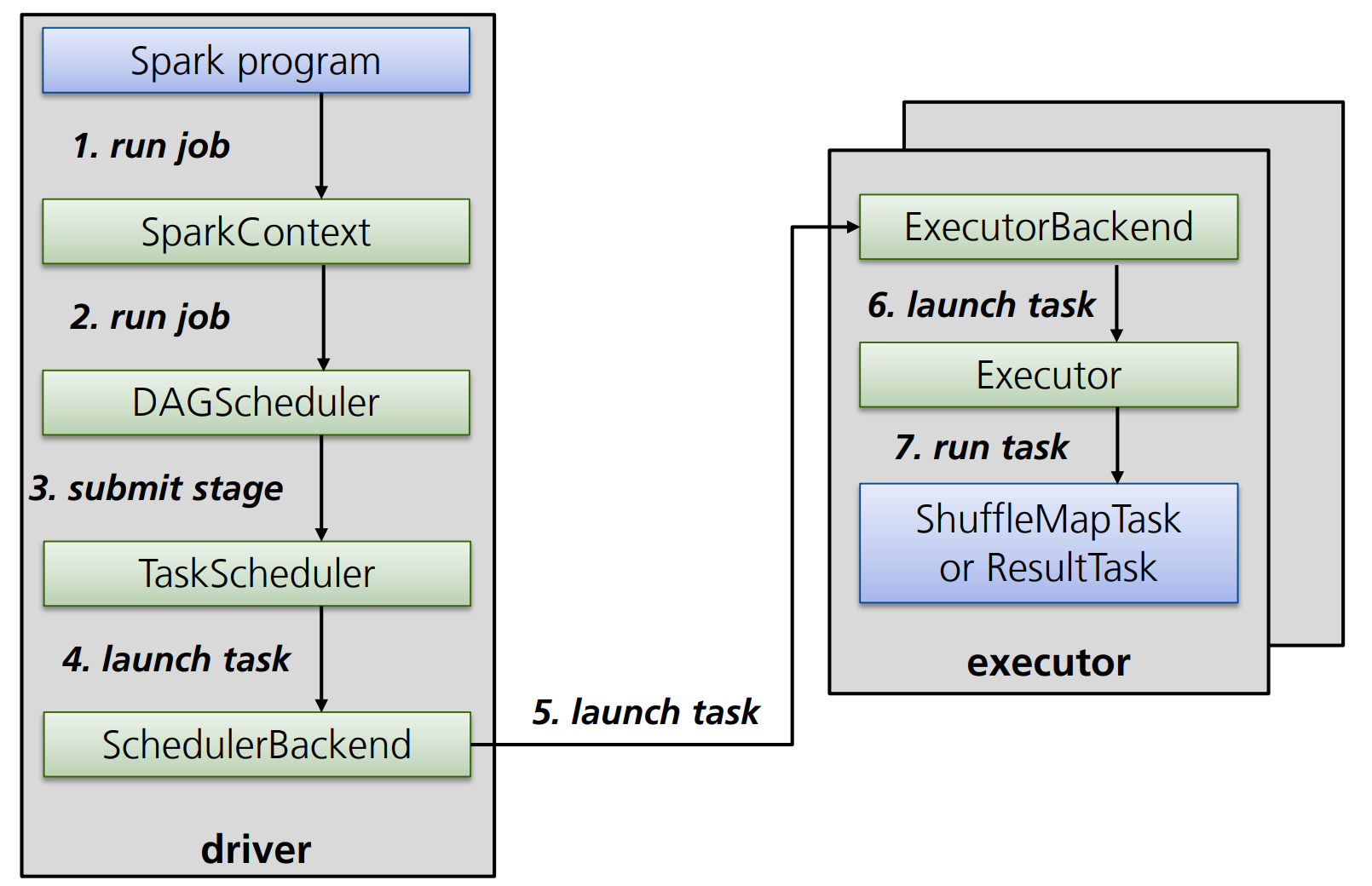
Definition: Erstellung und Lebenszyklus von Spark Jobs
Spark Jobs entstehen immer im Rahmen eines SparkContexts.
Wird auf einer Reihe von Operationen eine Trigger-Action ausgeführt, beginnt der DAGScheduler damit, entsprechende Tasks anzulegen und diese auf mehrere “shuffle-freie” Stages aufzuteilen sowie die Reihenfolge der Tasks zu optimieren, bzw. überflüssige Tasks zu entfernen.
Anschließend sendet der TaskScheduler die so entstandenen Stages an das Cluster und kümmert sich darum, dass Tasks bei Fehlern erneut ausgeführt werden.
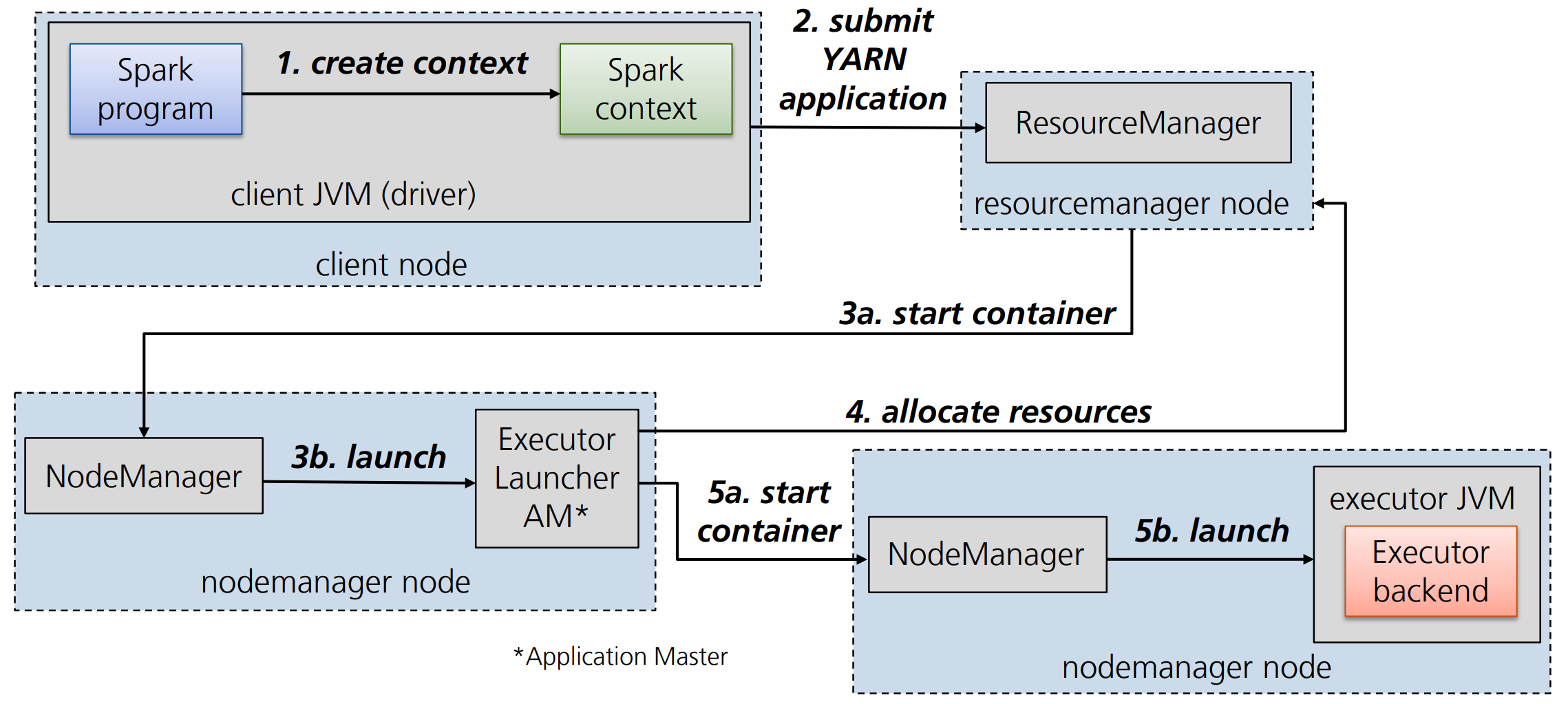
Definition: Spark auf YARN
In dem Kontext von YARN läuft der Spark-Driver (DAGScheduler, TaskScheduler, SchedulerBackend) auf dem Application Master. Die Spark Executors werden in den Containern weiterer Worker Nodes gestartet.