Typen:Beispiele:Konstrukte:- Schema on read
Generalisierungen:Eigenschaften:Involvierte Definitionen:Veranstaltung: DEDSReferenz:- @storl2024 (KE5, Analyse von Big Data)
- MapReduce: Simplified Data Processing on Large Clusters. Dean and Gehmawat, Google 2004
⠀
Definition: MapReduce
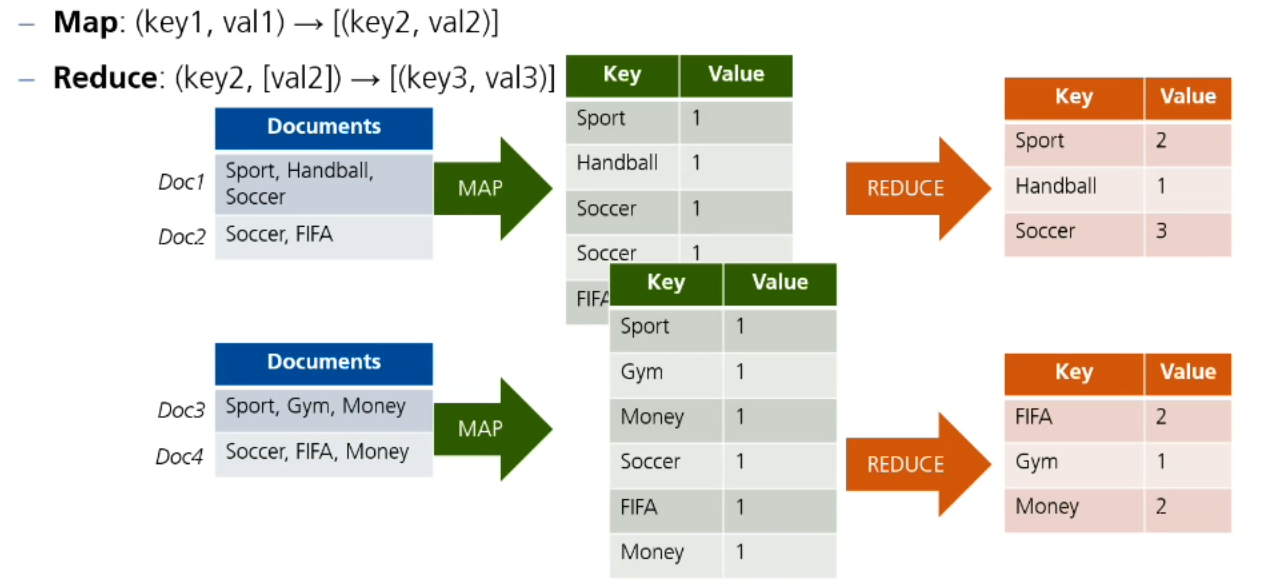
Als MapReduce definieren wir ein Paradigma zur parallelen Verarbeitung großer Datenmengen. Es besteht aus zwei Hauptphasen:
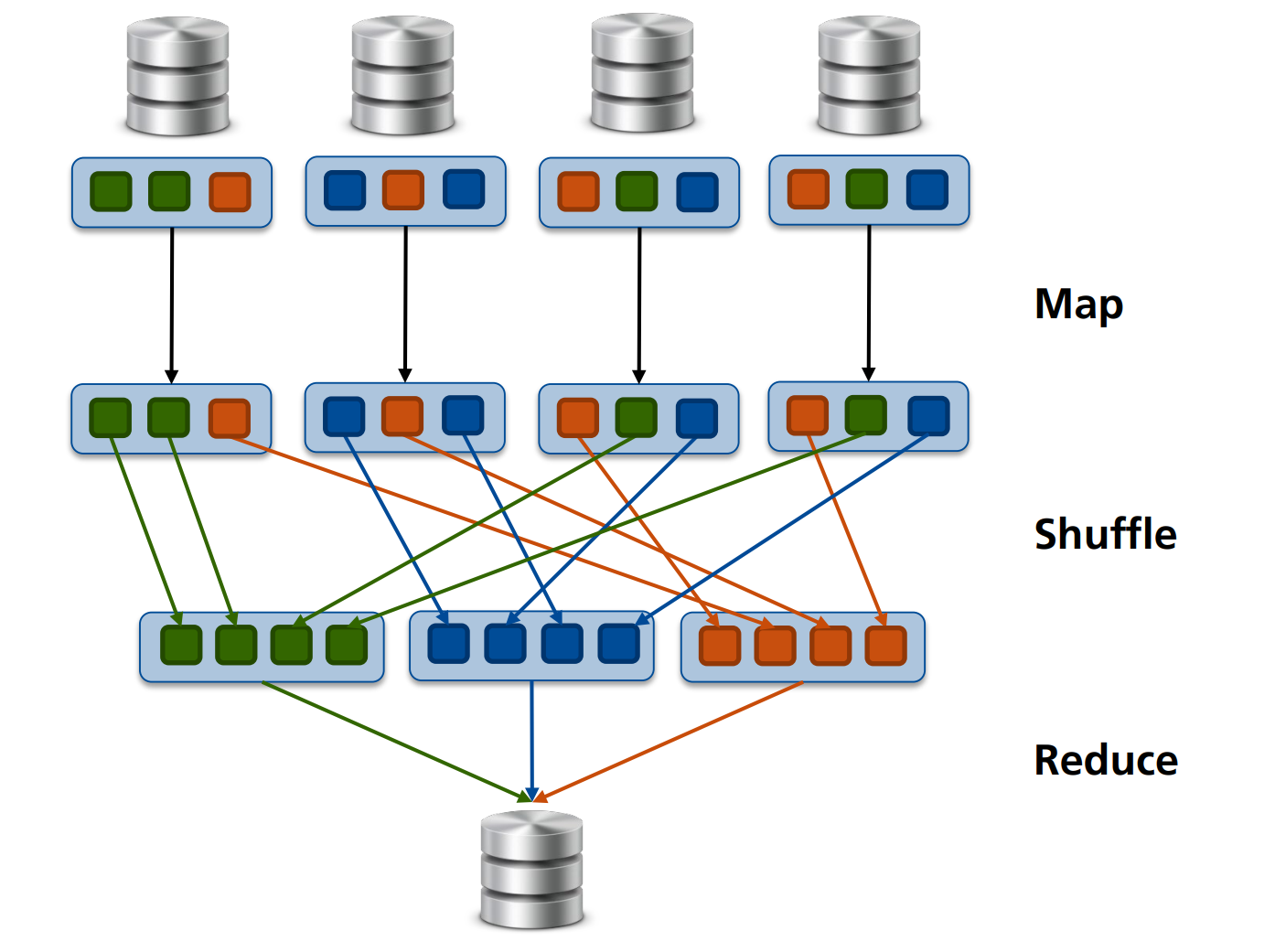
- Map: Verarbeitet Eingabedaten und erzeugt Zwischenpaare (Key, Value).
- Shuffle: Die Zwischenpaare (Key, Value) werden so auf neue Nodes verteilt, dass jeder Node alle Werte mit einem bestimmten Key erhält.
- Reduce: Aggregiert diese Paare und erzeugt die Endergebnisse.
In beiden Phasen werden die Bestandsdaten nicht verändert.
Dieses Modell ermöglicht eine skalierbare und effiziente Datenverarbeitung in verteilten Systemen.
Weitere Vorteile sind:
- Kein Nebeneffekte durch andere andere Operationen, da die Daten immutable behandelt werden,
- Keine Zugriffskonflikte, da die Daten direkt auf ihren Nodes verarbeitet werden,
- Keine Deadlocks,
- Keine Race Conditions.
Anmerkung
Beispiel: Word Count
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { … public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, …) … { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); } } } public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator <IntWritable> values, OutputCollector<Text, IntWritable> output, …) … { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } }