Als Average-Link-Clustering definieren wir ein agglomeratives Verfahren mit Distanzfunktion:
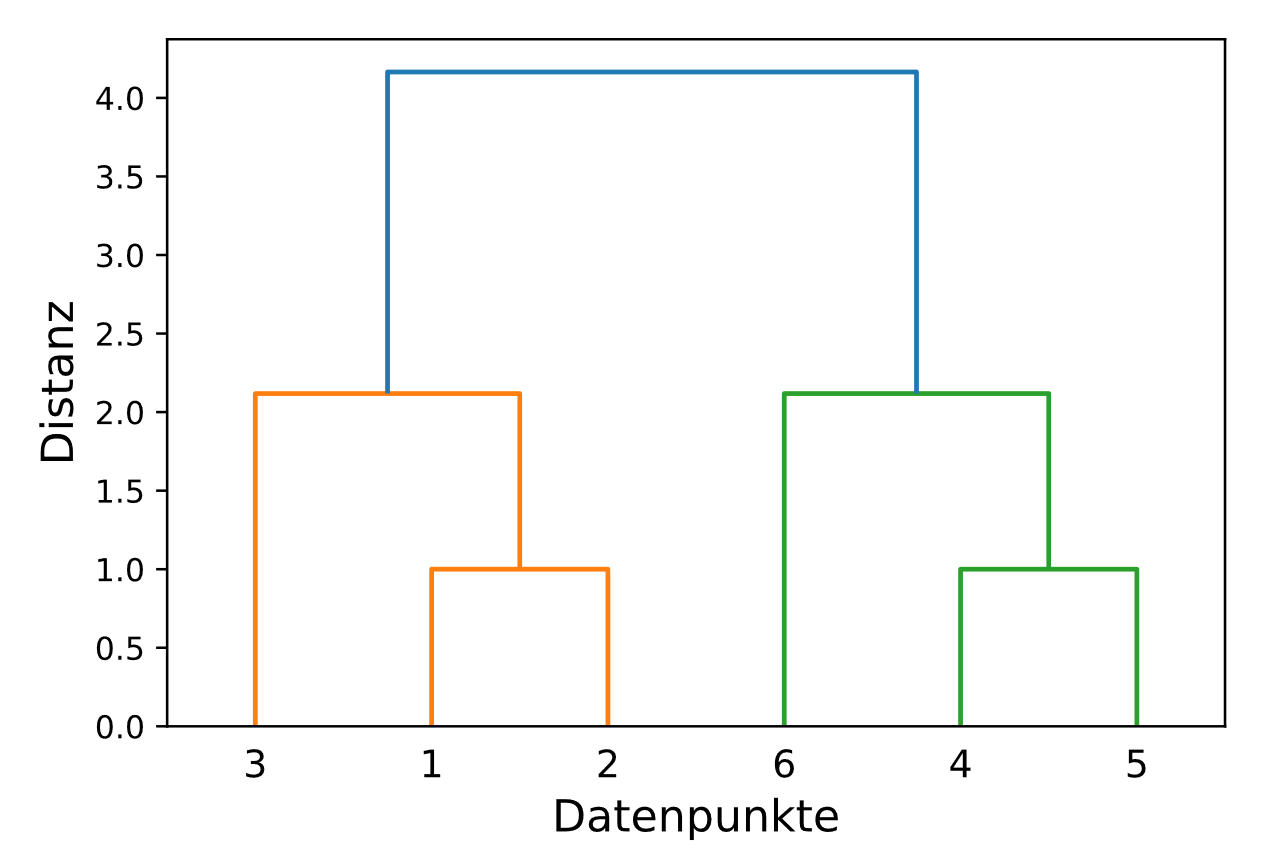
Die durch Average-Link-Clustering erzeugten Cluster sind in der Regel “ausgeglichen”, wie das folgende quantitative Dendrogramm zeigt:
Anmerkung
Anfälligkeit ggü. Skalierung
Wie die meisten distanzbasierten Verfahren ist auch das Average-Link-Clustering anfällig gegenüber der Skalierung von Merkmalen.
Es bietet sich also eine z-Transformation an.
Average-Link-Clustering mit scikit-learn
In Python erhalten wir ein Average-Link-Clustering mit durch:
E = ((12,7),(10,8),(10,7.5),(15,5),(16,9),(18,8))from sklearn.cluster import AgglomerativeClusteringcluster = AgglomerativeClustering(n_clusters=2, linkage="average").fit_predict(E)print(cluster)
Dabei gibt an, wie viele Cluster in der Variable cluster enthalten sein sollen. Betrachtet man ein quantitatives Dendrogramm, so gibt sozusagen die “Ebene” an, aus der die Cluster gewählt werden.