Involvierte Definitionen:Veranstaltung: EMLReferenz:
⠀
Definition: Segment Anything Model (SAM)
SAM besteht aus den folgenden Komponenten:
- Image Encoder
- Dense Prompt (Mask)
- Sparse Prompts (Points, Box, Text)
- Prompt Encoder
- Mask Decoder
Das grobe Vorgehen ist wie folgt:
- Vorbereitung
- SAM erhält ein Eingabebild
- Mittels eines vortrainierten Vision Transformers wird das Eingabebild in eine Reihe von Image Embeddings umgewandelt.
- Diese Embeddings können nun für verschiedene, wechselnde Prompts genutzt werden.
- Prompting
- Nutzer können verschieden Prompts angeben.
- Masken
- Eigezeichnete Masken werden mithilfe eines CNNs transformiert.
- Die transformierten Masken werden den Bild-Embedding-Vektoren hinzuaddiert.
- Boxen, Punkte, Text
- werden mittels Promptencoder in Vektoren umgewandelt.
- Die so erzeugten Vektoren werden gemeinsam mit den Image Embeddings in den Mask-Decoder eingegeben.
- Der Mask-Decoder produziert schließlich die Output-Masken.
Definition: SAM-Decoder
Der SAM-Decoder produziert stets vier Segmentierungs-Masken. Je nach Konfiguration werden dem Nutzer nur die erste oder die letzten drei Masken zurückgegeben.
Dabei segmentieren die Masken jeweils unterschiedliche Detail-Level innerhalb des Bildes (mit je einem Confidence-Score):
Der Decoder lässt sich grob in drei Teilschritte unterteilen:
- (Image- und Positional-Embedding für das Input-Bild generieren)
- Embeddings für die Prompts generieren
- Low-Res Segmentierungsmasken und Confidence in verschiedenen Größen erstellen
- Die Segmentierungsmasken auf die Größe des Inputbildes hochskalieren

.png)
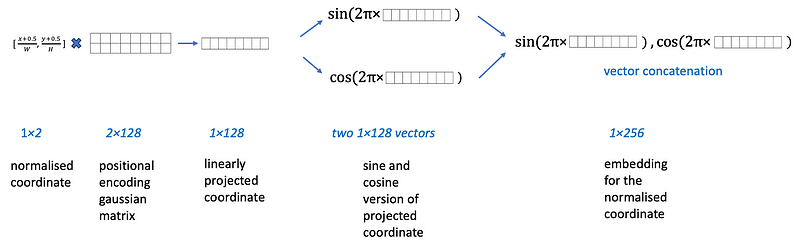
Positional Encoding
Um dem Modell an verschiedenen Stellen mitteilen zu können, auf welche Stelle im Bild sich verschiedene Vektoren befinden, wird ein statisches Positional Encoding genutzt.
Dieses Encoding wird auf Basis mehrerer Sinus und Cosinus Frequenzen erstellt und ist während des gesamten Trainingsprozesses fest. Das Embedding eines Punktes kann dann wie folgt berechnet werden:
Um das gesamte
-Embedding zu erzeugen, muss diese Transformation nur für alle Punkte durchgeführt werden. Alternativ könnte auch ein lernbares Positional Encoding genutzt werden.
Embeddings für das Bild generieren
Zunächst wird das Bild auf
geresized, damit die Kontextgröße für die involvierten Transformer stets gleich ist. Anschließend wird der ViT-Encoder eines MAE genutzt, um
Embeddingvektoren mit jeweils 256 Dimensionen zu erzeugen. Jeder Embeddingvektor repräsentiert mit seinen 256 Dimensionen einen
-Pixelausschnitt des ursprünglichen Bildes.
Embeddings des Dense Prompts (Prompt-Maske) generieren
Die Prompt-Maske wird zunächst auf
geresized. Anschließend wird ein lernbarer Conv-Layer ausgeführt, der eine
Feature-Map produziert.
Embeddings des Sparse Prompts (Points, Box, Text) generieren
Für jeden Prompt werden ein oder mehrere
-dimensionale Embeddings erstellt.
- Jeder Punkt trägt ein Embedding bei,
- Jede Maske trägt zwei Embeddings bei (eines für die linke obere und eines für die rechte untere Ecke),
- Jedes Wort/jeder Text trägt ein Embedding bei
Erzeugung des Punkt-Embeddings
Jedes Punkt-Embedding wird als Summe zweier, zunächst separater
-dimensionaler Embeddings erstellt:
- Einem Embedding für die Art des Punktes (positiv oder negativ)
- Einem Embedding für die Koordinaten des Punktes (auf Basis des Positional Encodings)
.png)
Erzeugung des Box-Embeddings
Wie Punkt Embeddings, nur mit zwei Embeddings (oben links und unten rechts).
Erzeugung des Text-Embeddings
Das Text-Embedding wird zur Inferenz mithilfe des CLIP-Text-Encoders erzeugt.
Im Training wird das “Text-Embedding” mithilfe des CLIP-Image-Encoders erzeugt. Die Hypothese ist, dass die beiden Embeddings (Text und Image-Embedding) sich stark ähneln, weil die Zielsetzung von CLIP ist, die Kosinus-Ähnlichkeit zwischen den beiden Embeddings (textuelle Beschreibungen eines Bildes und das Bild selber) zu maximieren.
(Unter anderem) wegen genau dieser Ähnlichkeit nutzt SAM die Encoder von CLIP.
IoU-Tokens und Mask-Tokens
Bei den IoU- und Mask-Tokens handelt es sich jeweils um trainierbare Vektoren.
"Low-Res" Segmentierungsmasken und Confidence in verschiedenen Größen erstellen
Der Mask-Decoder erhält die so erstellten Embeddings als Input und produziert zwei Outputs:
- 4 “Low-Res” Segmentierungsmasken mit einer Auflösung von
- 4 Floats, die die Confidence der jeweiligen Segmentierungsmasken repräsentieren.
In einem ersten Schritt summiert der Decoder Image Embedding und Embedding des Dense Prompts miteinander. Anschließend wird das so erzeugte Embedding gemeinsam mit allen Tokens an einen Transformer weitergegeben:
Der Transformer produziert vier angereicherte Outputs:
iou_token: werden zur Berechnung der Confidence genutzt,mask_tokens: werden als “Segmentation Head” zur Berechnung der Low Res Maske genutzt,sparse_prompt_embeddings: werden ignoriert,src2: angereichertes Input-EmbeddingMithilfe eines normalen Feed Forward-Netzwerks werden die Mask Tokens auf die Dimension
reduziert und mit den (um den Faktor hochskalierten) angereicherten Image Embeddings multipliziert:
Die Matrixmultiplikation
resultiert in einem neuen Vektor mit Dimension . Dieser Vektor wird abschließend noch so verformt, dass seine Dimensionen der Outputgröße
entspricht, die wir für die Low Res Segmentierungsmasken erwarten. Die
iou_tokenswerden durch ein einfaches Feed Forward-Netzwerk verarbeitet, um die vier Confidence Scores vorherzusagen.
.png)
.png)
Der Transformer
Der zur Vorhersage der Low-Res Segmentierungsmasken genutzte (Two-Way) Transformer berechnet gleich drei verschiedene Attentions:
- Self-Attention innerhalb des
sparse_prompt_embedding- Cross-Attention zwischen
sparse_prompt_embedding(als query)image_embedding+dense_mask_embedding(als key und value)- Cross-Attention zwischen
image_embedding+dense_mask_embedding(als query)sparse_prompt_embedding(als key und value)