Konstrukte:Involvierte Definitionen:Veranstaltung: EMLReferenz: @radford2021
⠀
Definition: CLIP-Embedding
Die grundlegende Idee von CLIP ist es, Bildbeschreibungen nicht als “1 out of n”-Classes Problem zu betrachten. Statt die “beste Beschreibung” eines Bildes vorherzusagen, trainiert CLIP zwei Encoder:
- Text-Encoder: Erhält einen Text als Input und produziert ein Embedding.
- Image-Encoder: Erhält ein Bild als Input und produziert ebenfalls ein Embedding.
Für passenden Bild-Text-Paare versucht CLIP nun, die Kosinus-Ähnlichkeit zu maximieren - für unpassende Paare versucht CLIP sie zu minimieren.
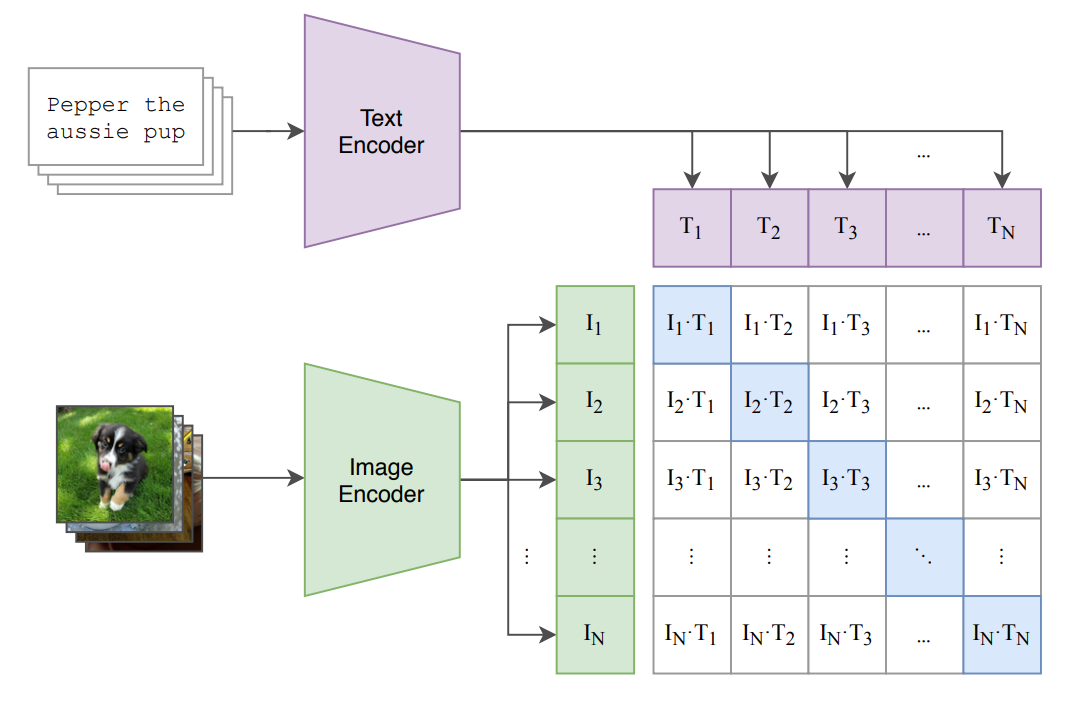
Als Modell für den Text-Encoder wird unter anderem ein normaler Text-Transformer genutzt. Als Embedding Vektor wird das finale Embedding des End-of-Sequence-Tokens
[EOS]genutzt.Als Modell für den Image-Encoder wird unter anderem ein Vision Transformer (ViT) genutzt, das Embedding wird ähnlich wie in dem ViT-Paper aus dem
[class]-Token extrahiert.Die Illustration veranschaulicht das Trainingsverfahren. Auf der Diagonalen befinden sich die Embeddings der “passenden” Bild-Text-Paare (insgesamt
-Stück), abseits der Diagonalen die Embeddings der “unpassenden” Paare (insgesamt -Stück). Für jedes Paar wird die Kosinus-Ähnlichkeit berechnet und während des Trainings entsprechend maxi- oder minimiert.